If you manage a Kubernetes cluster, you will need to renew the certificate once a year. Lucky for us Kubernetes provides an easy way to renew all the certificates needed.
The single command needed to renew Kubernetes certificates is kubeadm certs renew all. Let’s see the details of how it is done in this tutorial.
Sudo Privileges
Before starting, we make sure that we will have no permission issues on the installation and configuration. Go to your Kubernetes master node and type this command
sudo su
Backup Old Certificates
Before we renew the certificate, it is better to back up our existing configuration & certificate so we can use it later if the renewing process fails. We can copy them to /tmp folder on your Kubernetes master node.
mkdir /tmp/k8s-backup
cp /etc/kubernetes/*.conf /tmp/k8s-backup
cp -r /etc/kubernetes/pki /tmp/k8s-backup
Renew Certificates
First, check the expiration date of our cluster certificates by typing this command on your Kubernetes master node:
kubeadm certs check-expiration
You will get the expiration date of each component like this one:
root@k8s-master:/home/bagus# kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Nov 21, 2024 22:53 UTC 364d ca no
apiserver Nov 21, 2024 22:53 UTC 364d ca no
apiserver-etcd-client Nov 21, 2024 22:53 UTC 364d etcd-ca no
apiserver-kubelet-client Nov 21, 2024 22:53 UTC 364d ca no
controller-manager.conf Nov 21, 2024 22:54 UTC 364d ca no
etcd-healthcheck-client Nov 21, 2024 22:53 UTC 364d etcd-ca no
etcd-peer Nov 21, 2024 22:53 UTC 364d etcd-ca no
etcd-server Nov 21, 2024 22:53 UTC 364d etcd-ca no
front-proxy-client Nov 21, 2024 22:53 UTC 364d front-proxy-ca no
scheduler.conf Nov 21, 2024 22:54 UTC 364d ca no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Nov 19, 2033 22:53 UTC 9y no
etcd-ca Nov 19, 2033 22:53 UTC 9y no
front-proxy-ca Nov 19, 2033 22:53 UTC 9y no
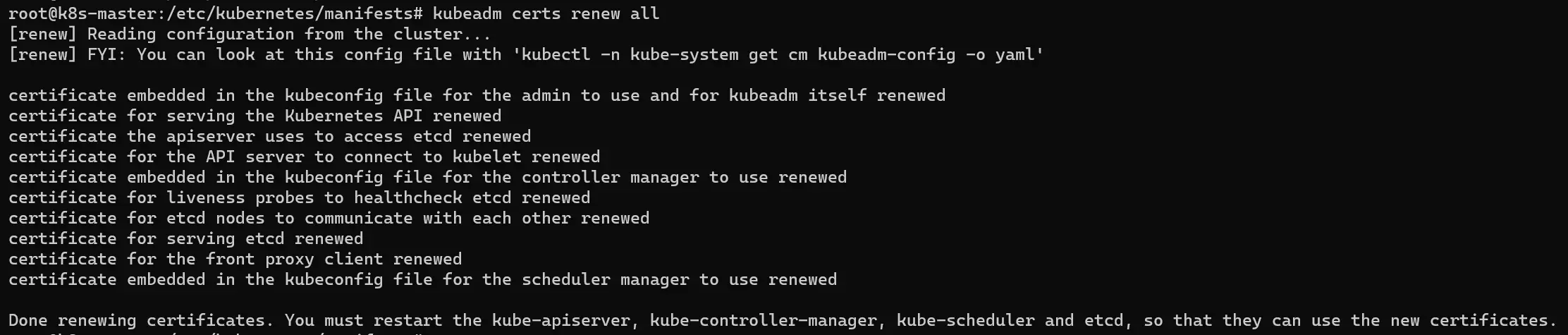
To renew our certificates, we just need this one command:
kubeadm certs renew all
You can confirm that the certificate is renewed by typing
kubeadm certs check-expiration
You will see the expiration date is updated
root@k8s-master:/home/bagus# kubeadm certs check-expiration [check-expiration] Reading configuration from the cluster... [check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED admin.conf Nov 21, 2024 23:02 UTC 364d ca no apiserver Nov 21, 2024 23:02 UTC 364d ca no apiserver-etcd-client Nov 21, 2024 23:02 UTC 364d etcd-ca no apiserver-kubelet-client Nov 21, 2024 23:02 UTC 364d ca no controller-manager.conf Nov 21, 2024 23:02 UTC 364d ca no etcd-healthcheck-client Nov 21, 2024 23:02 UTC 364d etcd-ca no etcd-peer Nov 21, 2024 23:02 UTC 364d etcd-ca no etcd-server Nov 21, 2024 23:02 UTC 364d etcd-ca no front-proxy-client Nov 21, 2024 23:02 UTC 364d front-proxy-ca no scheduler.conf Nov 21, 2024 23:02 UTC 364d ca no CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED ca Nov 19, 2033 22:53 UTC 9y no etcd-ca Nov 19, 2033 22:53 UTC 9y no front-proxy-ca Nov 19, 2033 22:53 UTC 9y no
To make sure our control plane is using the newest certificate, we need to restart the kube-apiserver, kube-controller-manager, kube-scheduler, and etcd, so they read the new certificate file. To do that, we can move their manifest to temporary locations one by one.
Restart API Server Pod
Let’s start with kube-apiserver. Because we are messing with the control plane, the kubectl command will not work properly here. So we can check their status using the containerd command like this
crictl -r unix:///run/containerd/containerd.sock ps
First, make sure the API server is running
root@k8s-master:/home/bagus# crictl -r unix:///run/containerd/containerd.sock ps | grep kube-apiserver 23e7455c1893e 7fe0e6f37db33 14 minutes ago Running kube-apiserver 0 f1c0570fe0d86 kube-apiserver-k8s-master
Move the manifest to a temporary folder
mv /etc/kubernetes/manifests/kube-apiserver.yaml /tmp
After a while, you will notice the API server is missing
root@k8s-master:/etc/kubernetes/manifests# crictl -r unix:///run/containerd/containerd.sock ps | grep kube-apiserver
root@k8s-master:/etc/kubernetes/manifests#
Move the manifest back from the temporary folder to the original place
mv /tmp/kube-apiserver.yaml /etc/kubernetes/manifests
After a while, the API server will back to running status
root@k8s-master:/etc/kubernetes/manifests# crictl -r unix:///run/containerd/containerd.sock ps | grep kube-apiserver b3d09c446e612 7fe0e6f37db33 9 seconds ago Running kube-apiserver 0 f06a71451213b kube-apiserver-k8s-master
Restart Controller Manager Pod
First, make sure the controller manager is running
root@k8s-master:/etc/kubernetes/manifests# crictl -r unix:///run/containerd/containerd.sock ps | grep kube-controller-manager 1916adb941070 d058aa5ab969c 3 minutes ago Running kube-controller-manager 1 907fda45461ad kube-controller-manager-k8s-master
Move the manifest to the temporary folder
mv /etc/kubernetes/manifests/kube-controller-manager.yaml /tmp
After a while, you will notice the controller manager is missing
root@k8s-master:/etc/kubernetes/manifests# crictl -r unix:///run/containerd/containerd.sock ps | grep kube-controller-manager
root@k8s-master:/etc/kubernetes/manifests#
Move the manifest back from the temporary folder to the original place
mv /tmp/kube-controller-manager.yaml /etc/kubernetes/manifests
After a while, the controller manager will back to running status
root@k8s-master:/etc/kubernetes/manifests# crictl -r unix:///run/containerd/containerd.sock ps | grep kube-controller-manager bc83a56a4b3d8 d058aa5ab969c 10 seconds ago Running kube-controller-manager 0 61c551ffacaed kube-controller-manager-k8s-master
Restart Scheduler Pod
First, make sure the Scheduler is running
root@k8s-master:/etc/kubernetes/manifests# crictl -r unix:///run/containerd/containerd.sock ps | grep kube-scheduler 023b5f2a3ab60 e3db313c6dbc0 5 minutes ago Running kube-scheduler 1 391207efd986d kube-scheduler-k8s-master
Move the manifest to the temporary folder
mv /etc/kubernetes/manifests/kube-scheduler.yaml /tmp
After a while, you will notice the scheduler is missing
root@k8s-master:/etc/kubernetes/manifests# crictl -r unix:///run/containerd/containerd.sock ps | grep kube-scheduler
root@k8s-master:/etc/kubernetes/manifests#
Move the manifest back from the temporary folder to the original place
mv /tmp/kube-scheduler.yaml /etc/kubernetes/manifests
After a while, the scheduler will back to running status
root@k8s-master:/etc/kubernetes/manifests# crictl -r unix:///run/containerd/containerd.sock ps | grep kube-scheduler 499482089ba6a e3db313c6dbc0 8 seconds ago Running kube-scheduler 0 db2c517b6d8a7 kube-scheduler-k8s-master
Restart etcd Pod
First, make sure the etcd is running
root@k8s-master:/home/bagus# crictl -r unix:///run/containerd/containerd.sock ps | grep etcd 1ec1f23d6afd9 73deb9a3f7025 2 days ago Running etcd 0 33d04c480952c etcd-k8s-master
Move the manifest to the temporary folder
mv /etc/kubernetes/manifests/etcd.yaml /tmp
After a while, you will notice the etcd is missing
root@k8s-master:/home/bagus# crictl -r unix:///run/containerd/containerd.sock ps | grep etcd
root@k8s-master:/home/bagus#
Move the manifest back from the temporary folder to the original place
mv /tmp/etcd.yaml /etc/kubernetes/manifests
Notes!
I notice that the etcd pod needs more time to start compared to another controller pod, it takes up to ~5 minutes in my case.
After a while, the etcd will back to running status
root@k8s-master:/etc/kubernetes/manifests# crictl -r unix:///run/containerd/containerd.sock ps | grep etcd 91ecdfacd0ff2 73deb9a3f7025 12 seconds ago Running etcd 0 0b72aff317cb5 etcd-k8s-master
Done! Congratulations, now your Kubernetes running using the newest certificates.
If you have multiple master nodes on your Kubernetes Cluster, you can do the same steps that are explained in this article and execute them on each master node, starting from renewing the certificates until restarting the control plane pod.