Did you know that Kubernetes has the ability to automatically scale your pods up, down, in, and out? This feature is called autoscaling.
Autoscaling is a critical feature in Kubernetes that ensures your applications can handle varying loads by automatically adjusting the number of running instances. This means your applications can respond to traffic spikes without manual intervention and conserve resources during low-traffic periods.
In this tutorial, we’ll delve into the two primary types of autoscaling in Kubernetes: Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA). We’ll also provide a step-by-step guide on how to install and use them.
Understanding Horizontal Pod Autoscaler (HPA)
Horizontal Pod Autoscaler is a feature in Kubernetes that automatically scales the number of pod replicas based on observed CPU utilization (or other select metrics). It is particularly useful for scaling stateless applications that can run multiple instances independently.
How HPA Works:
- Metrics Server: HPA relies on the Metrics Server, which collects resource usage data.
- Autoscaling Controller: The HPA controller checks the metrics periodically and adjusts the number of pods based on the specified thresholds.
Installing the Metrics Server:
Before using HPA, ensure that the Metrics Server is installed in your cluster.
You can run this command to install the Metrics Server:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
To verify installation, use this command:
kubectl get deployment metrics-server -n kube-system
You will get this response
NAME READY UP-TO-DATE AVAILABLE AGE
metrics-server 1/1 1 1 3m42s
With a metric server available, you can check the Kubernetes node cpu and memory usage, for example like this:
kubectl top node
You will get the node’s usage like this one
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-single-node 79m 3% 973Mi 49%
You can even check the cpu and memory usage on Pods level
kubectl top pod --all-namspaces
And it will show you all of the pod’s cpu and memory usage like this
NAMESPACE NAME CPU(cores) MEMORY(bytes)
kube-system coredns-7b98449c4-rmgjp 2m 12Mi
kube-system local-path-provisioner-595dcfc56f-qbkg5 1m 6Mi
kube-system metrics-server-cdcc87586-k7zjm 6m 17Mi
kube-system svclb-traefik-415e0e61-b9gmk 0m 0Mi
kube-system traefik-d7c9c5778-46l28 1m 33Mi
Creating a HPA:
Here’s an example to create an HPA for a deployment named my-deployment. Note that we must define the pod’s resources to be able to use the HPA.
Set Up Your deployment.yaml with resources defined
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
replicas: 1
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: nginx
resources:
requests:
memory: "64Mi"
cpu: "125m"
limits:
memory: "128Mi"
cpu: "250m"
Apply this deployment
kubectl apply -f deployment.yaml
Create an hpa.yaml for the deployment
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: my-deployment-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
Apply the HPA
kubectl apply -f hpa.yaml
Verify HPA
kubectl get hpa
You will see the resource percentage of the pod
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
my-deployment-hpa Deployment/my-deployment cpu: 1%/50% 1 10 1 69s
In this example, HPA will scale the my-deployment deployment’s pod replicas between 1 and 10 based on CPU utilization, targeting 50% average CPU usage.
Understanding Vertical Pod Autoscaler (VPA)
Vertical Pod Autoscaler adjusts the resource requests and limits of running pods. It is beneficial for stateful applications or applications where horizontal scaling is not feasible.
How VPA Works:
- Admission Controller: VPA uses an admission controller to set resource requests and limits for new pods.
- Recommender, Updater, and Admission Controller: These components continuously monitor resource usage, provide recommendations, and update running pods.
Installing VPA:
First, Make sure the metric server is also installed. If not yet installed, you can see the HPA section where we install the metric server.
After that, check the compatibility table bellow.
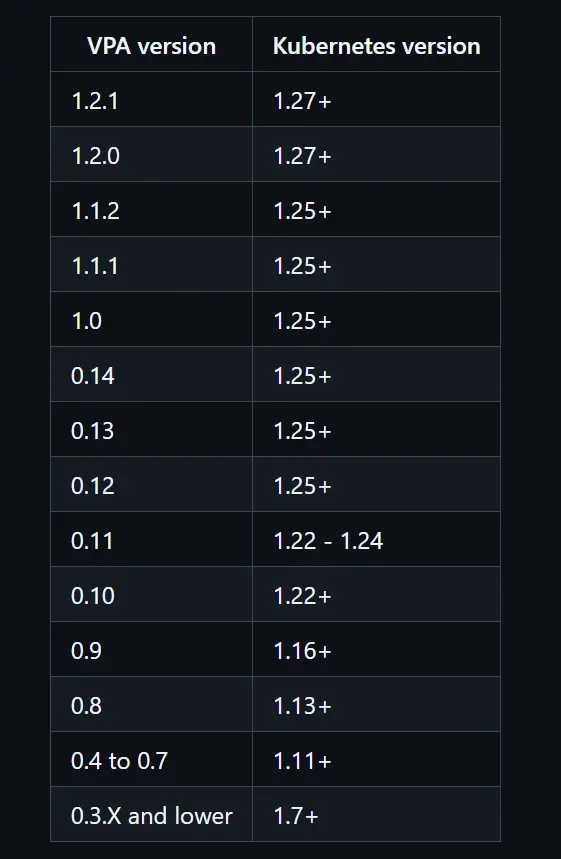
Since we use kubernetes version 1.30.1, we will use the 1.2version. To install VPA, run this command
kubectl apply -f https://raw.githubusercontent.com/kubernetes/autoscaler/vpa-release-1.2/vertical-pod-autoscaler/deploy/vpa-v1-crd-gen.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes/autoscaler/vpa-release-1.2/vertical-pod-autoscaler/deploy/vpa-rbac.yaml
We can change the version either 1.2, 1.1, or 1.0 based on your Kubernetes version.
Creating a VPA
Before applying VPA, set up Your deployment.yaml with resources defined
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment-2
spec:
selector:
matchLabels:
app: my-app-2
template:
metadata:
labels:
app: my-app-2
spec:
containers:
- name: my-container
image: nginx
resources:
requests:
memory: "64Mi"
cpu: "125m"
limits:
memory: "128Mi"
cpu: "250m"
Apply this deployment
kubectl apply -f deployment.yaml
Here’s an example to create a vpa.yaml for a deployment named my-deployment-2.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-deployment
updatePolicy:
updateMode: "Auto"
Notice the spec.updatePolicy.updateMode is set to Auto, there are 4 modes available for VPA update mode:
- “Auto”: VPA assigns resource requests on pod creation and updates them on existing pods using the preferred update mechanism. Currently, this is equivalent to “Recreate” (see below). Once restart-free (“in-place”) updates of pod requests are available, they may be used as the preferred update mechanism by the “Auto” mode.
- “Recreate”: VPA assigns resource requests on pod creation and updates them on existing pods by evicting them when the requested resources differ significantly from the new recommendation (respecting the Pod Disruption Budget, if defined). This mode should be used rarely, only if you need to ensure that the pods are restarted whenever the resource request changes. Otherwise, prefer the “Auto” mode, which may take advantage of restart-free updates once they are available.
- “Initial”: VPA only assigns resource requests on pod creation and never changes them later.
- “Off”: VPA does not automatically change the resource requirements of the pods. The recommendations are calculated and can be inspected in the VPA object.
Apply this VPA:
kubectl apply -f vpa.yaml
Check Recommendations
kubectl describe vpa my-vpa
In this example, VPA will automatically adjust the resource requests and limits of the pods in the my-deployment deployment.
Conclusion
Autoscaling is a powerful feature that can greatly enhance the performance and efficiency of your applications in a Kubernetes environment. By using Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA), you can ensure your applications are always running at optimal resource levels.
Horizontal Pod Autoscaler (HPA) helps you manage the number of pod replicas based on resource usage metrics, providing a simple and effective way to scale stateless applications.
Vertical Pod Autoscaler (VPA) adjusts the resource requests and limits of your pods, making it ideal for stateful applications or those where horizontal scaling isn’t feasible.
By following the steps outlined in this guide, you can install and configure both HPA and VPA in your Kubernetes cluster. This will enable your applications to handle varying loads efficiently, ensuring high availability and performance.
Remember, autoscaling is not a one-size-fits-all solution. Always test and monitor your autoscaling configurations to ensure they meet the specific needs of your applications.