Caching is one way to increase NodeJS application performance. Caching helps to reduce database calls, which are typically time-consuming. Redis is one tool that could help us.
Redis is a type of database.
Why are we using a database yet again? Wasn’t it previously stated that we need to reduce database calls because they take so long?
Yes, but because Redis performs much better than other databases, many people use it as a cache. Isn’t it better to make a database call to a faster database?
Why is Redis Good for Caching?
Redis has been labeled the world’s fastest database. Unlike other file-based databases, Redis is memory-based, meaning it stores data in memory.
Because it has the fastest performance, Redis can serve as a cache for your primary database, which could be MySQL, MongoDB, PostgreSQL, or another.
In the last section of the article, we also measured how our NodeJS application performs without cache vs. with cache using Redis.
How do I Cache in NodeJS?
The Application Topology
First, let’s draw a topology. This is a normal common topology where the user request some data to nodejs (1), and then nodejs do a query to MySQL (2), MySQL return the query results (3), and then nodejs give the response to the user (4).

This is a fine topology for websites with few users. However, if your users are getting higher, it will start to give an impact on the user. To solve the issue, we can add a cache (in this case Redis) that is geographically closer to the NodeJS to cache the database response on the first query. Let’s take a look at the new topology:
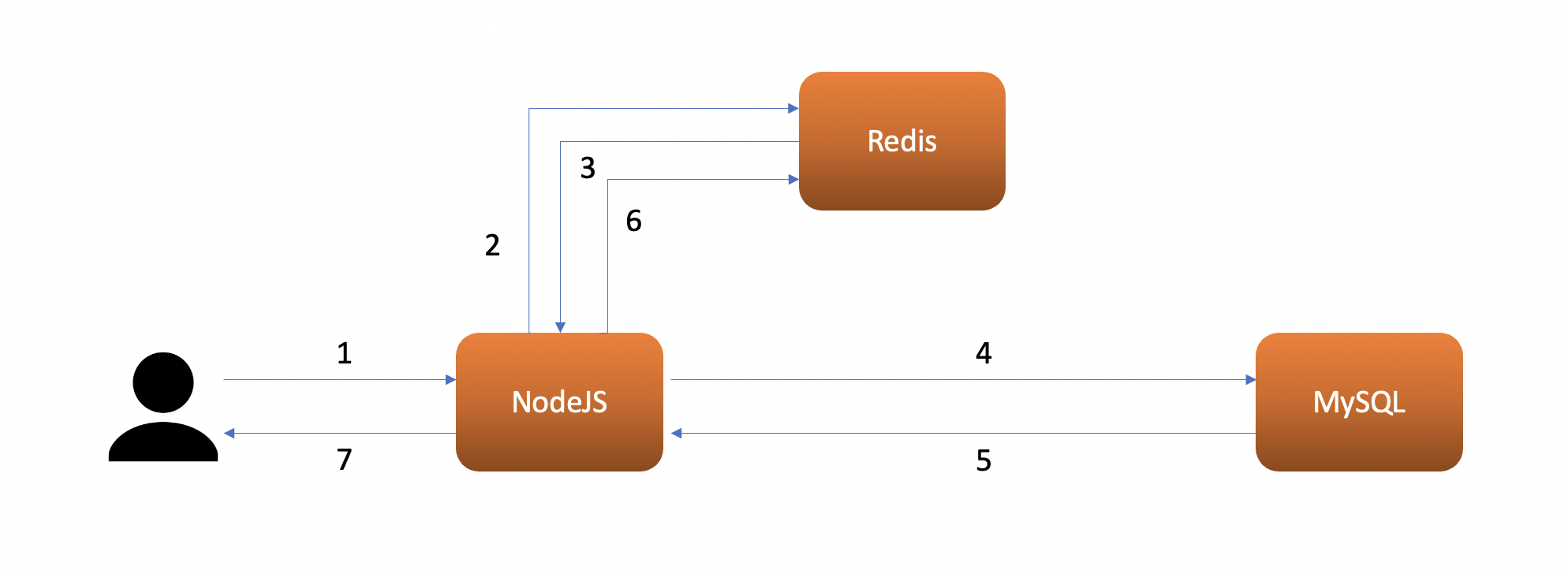
You see now that the nodejs will query to the cache first to see if there is a cache or not (2), if it is the first time the user request the data, then Redis will return nothing which means a cache miss (3), then the nodejs will do a query to the database (4), the database will return the query result (5), after that nodejs save the query result to cache asynchronously (6) while giving the response to the user (7).
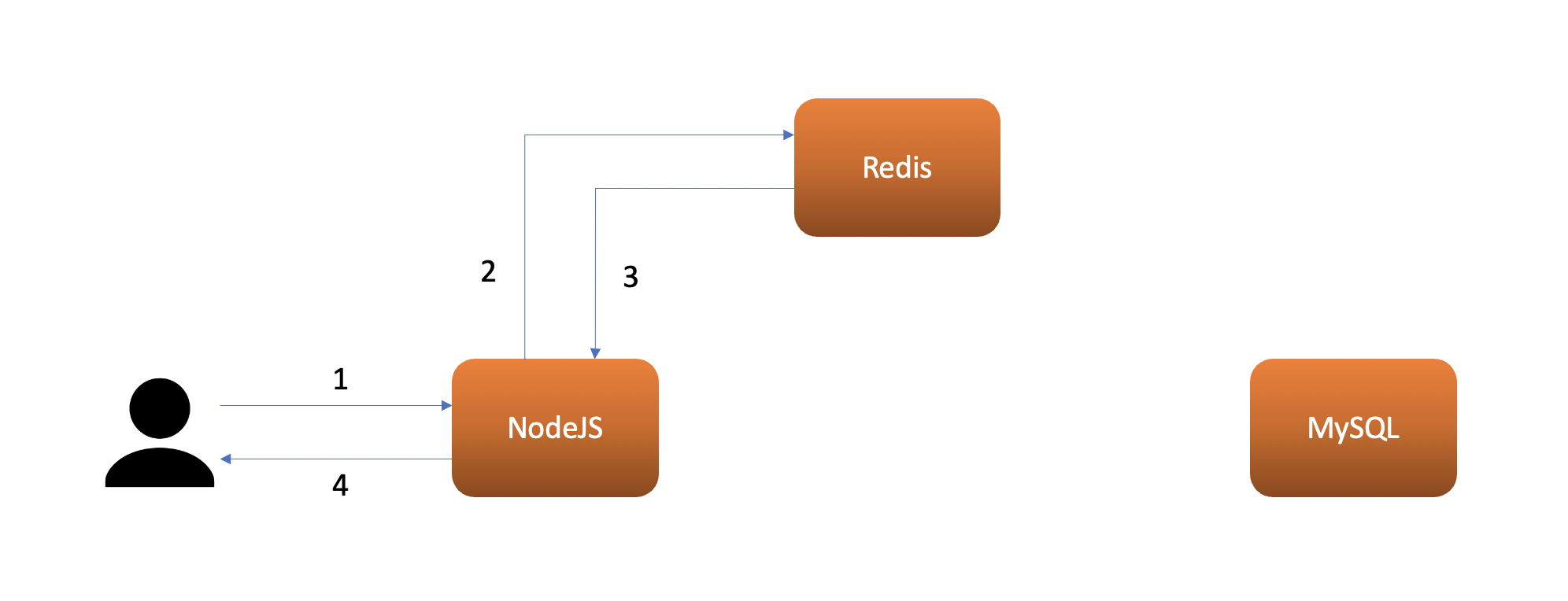
The next time the user requests the same data, nodejs will query the cache first to see if there is a cache or not (2), then this time Redis will return the data (3). After that, the nodejs can directly respond to the user (4) without doing a query to the main database.
This caching mechanism is called Cache aside and this is the most popular & easiest caching mechanism to implement.
The NodeJS Code
You can clone and see the source code yourself at my GitHub: Node-Redis Caching Application, or you can just follow this tutorial.
In this code we are using these stack:
fastifyas Webserver. Note: If you want to know why we preferfastifytoexpress, check my article here: Fastify vs Express Performance.ioredisas Redis client.mysql2as Mysql client.
First, we need to create a model that queries to Redis:
// src/models/cache.js
const { cacheExpired } = require("../configs")
const redis = require("../loaders/redis")
const getCache = async (key) => {
let result = JSON.parse(await redis.get(key))
return result
}
const setCache = async (key, value) => {
let stringifiedValue = JSON.stringify(value)
return await redis.setex(key, cacheExpired, stringifiedValue)
}
module.exports = {
getCache,
setCache
}
From the code above, we can see that the code is just a plain GET and SETEXcommands to Redis. But why do we use SETEX instead of SET? Because the cache doesn’t always contain the latest version of data, so we need the cache to be expired at some point. If the data rarely changed, you can set a longer expiration time. cacheExpired is the parameter we used to define the expired time here.
From the topology I made earlier, we know that the nodejs will always query the cache first. before we query the database, so I make a middleware to do the job. This is the root file of our project that explains the whole process:
// src/app.js
...
app.get("/products", async (req,res) => {
let result = await selectAllProduct()
res.status(200).send({
message: "get all products success",
products: result
})
})
app.get("/products/:id", async (req,res) => {
let productId = req.params.id
let result = await selectProductById(productId)
res.status(200).send({
message: "get all products success",
products: result
})
})
app.get("/products-with-cache", { onRequest: findAllProductsOnCache }, async (req,res) => {
let result = await selectAllProduct()
res.status(200).send({
message: "get all products success",
products: result
})
setCache("product-all", result)
})
app.get("/products-with-cache/:id", { onRequest: findProductOnCache }, async (req,res) => {
let productId = req.params.id
let result = await selectProductById(productId)
res.status(200).send({
message: "get all products success",
products: result
})
setCache("product-" + productId, result)
})
app.listen({ port,host }, () => {
console.log("app listen on port " + port)
})
For the testing propose, I made 2 routes that are using no cache and 2 routes that are using cache and are handled by 2 separate middlewares that are findAllProductsOnCache which is a cache of a single product, and findProductOnCache which is a cache of all products on the DB.
This is what the middleware looks like:
// src/middleware/cache.js
const { getCache } = require("../models/redis")
const findAllProductsOnCache = async (req, res) => {
let product = await getCache("product-all")
if (product && product != "null") {
res.status(200).send({
message: "get all products success from cache",
products: product
})
return
}
}
const findProductOnCache = async (req, res) => {
const productId = req.params.id
let product = await getCache("product-" + productId)
if (product && product != "null") {
res.status(200).send({
message: "get all products success from cache",
products: product
})
return
}
}
module.exports = {
findAllProductsOnCache,
findProductOnCache
}
We can see the marked code the first thing we do is to get the product from the cache, and then we will send the response to the user if the cache is found. If the cache is not found, then the application will run the main function defined in the src/app.js.
You can explore more of the code by cloning the repo.
How Much Faster Does Caching Make?
To answer this, we already do some load testing using Apache Bench to our code.
We try to load the system by doing 10k requests with 100 concurrencies by hitting 2 APIs on our code. This is the command we used:
ab -n 10000 -c 100 http://localhost:3000/products
ab -n 10000 -c 100 http://localhost:3000/products/17
The first one is an API to get All products on our MySQL database. There are 43 rows of 5-column data. The second one is an API to get only 1 product (row) from our Database, in this case, the product with an id of 17. We try to test each of the APIs 10 times to reduce the amount of error.
And these are the results:
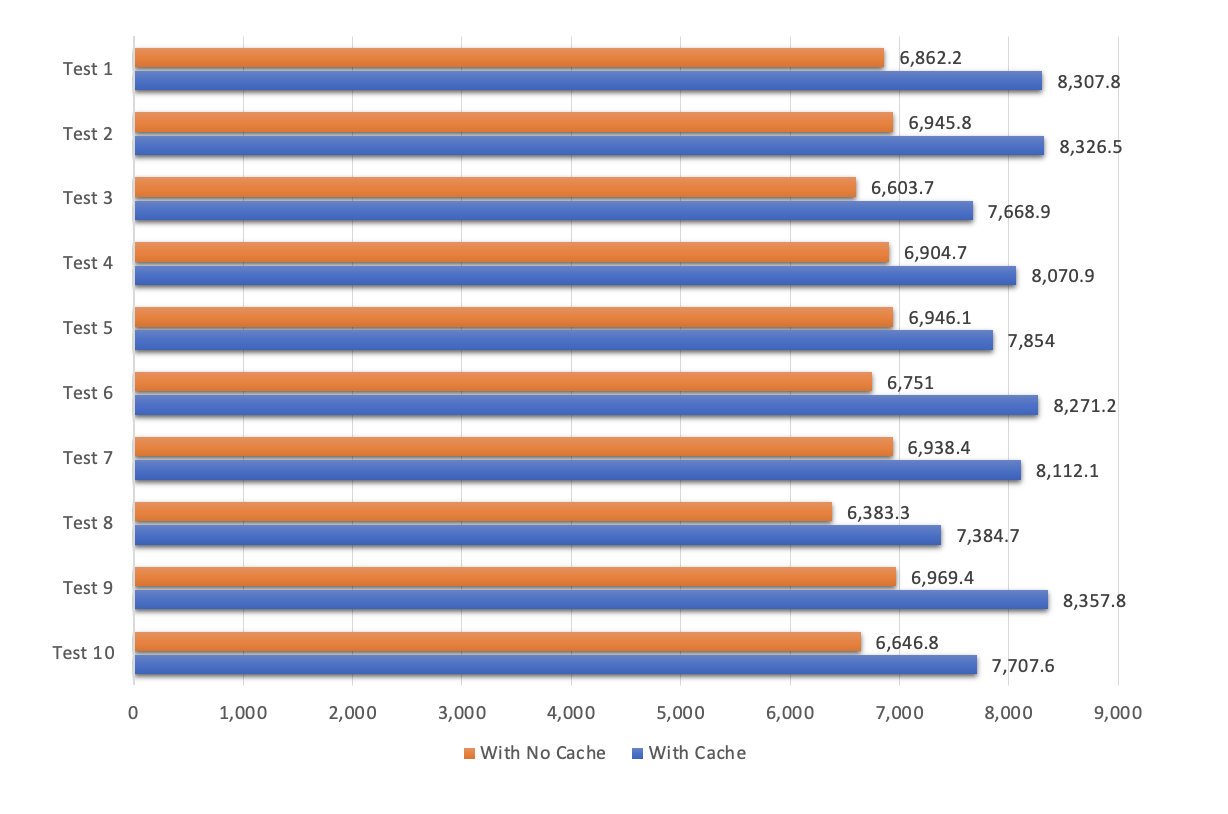
This chart shows the result of our first test, which is a query of all 43 rows of our products. As you can see that on average our application can serve around 6.8k req/s without caching and 8k req/s with caching. This is on average 17.8% improvement on the app performance.
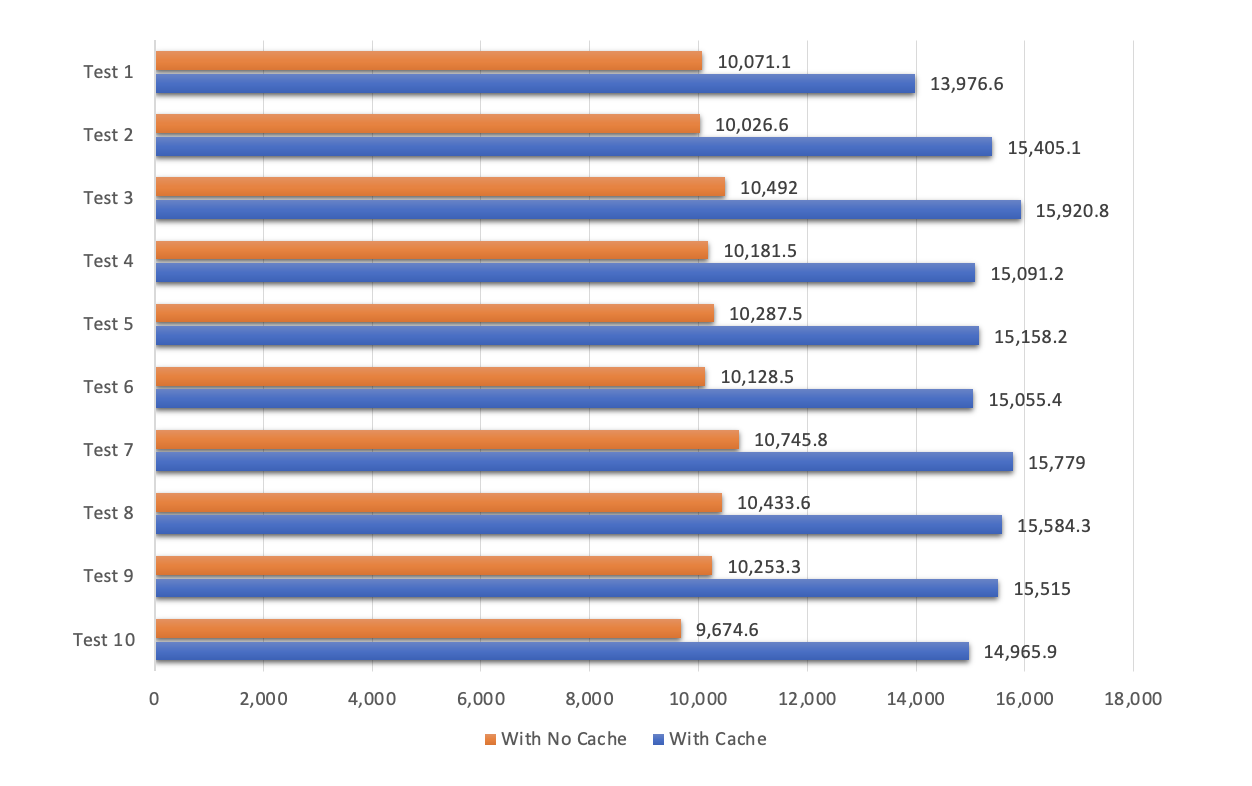
The second chart shows the result of our second test, that is query only 1 row of our product. As you can see that on average our application can serve around 10k req/s without caching and around 15k req/s with caching. This by average 49% improvement on the app performance
Conclusion
From this cache vs without cache performance test, we can see that caching with Redis gives you a performance boost for up to 49% on average.
We also see that smaller data gives better performance boost.
Of course, the performance will vary depending on the hardware resource, Redis location, MySQL location, and many more, but I hope this gives you a rough idea of how caching can give your NodeJS application a performance boost.
Please note that adding a cache will also increase the complexity of the application. You must test the right value for the cache expired time, so your application does not serve invalid data for the user.